
因为长期刷题速度比不上比赛场次,导致之前一直在刷几年前的题目。最近因为这个小破网站的缘故,刷题的热情一下就起来了。结果就发现自己变菜了很多是一方面,Codeforces也变化蛮大的。
然后呢,为了重新认识Codeforces的难度情况(其实主要为了划水),于是我下沉刷了一场Div3。结论是:我还是老老实实Div1吧,虽然最近确实菜了一点……
Div3感觉属于纯净水的级别,虽然我WA了一发,但主要是我阿兹海默症已经晚期的缘故。
A: Strange Table
题意:
n*m的矩阵。1-n*m依次排列,可以横着排,可以竖着排。
竖着排就是这样:

横着排就是这样:

现在给你一个竖着排里的一个数字x,问你:如果是横着排,在相同位置,数字是多少。
思路:
就是简单计算位置的问题。讲道理隔壁leetcode也找不出这么水的。
代码:

B: Partial Replacement
题意:
给你一个串,里面只有.和*。然后再给你一个数字k。现在要你把一些*变成x。要求
- 开头和结尾的
*必须要改成x。 - 两个
x之间间隔不能超过k
问:最少要改多少个*才能满足上述条件。(题目保证输入至少有一个*,且保证有解)
思路:
贪心。从开头的*开始,在不超过k的前提下,找尽可能远的*。
证明:
祖训:贪心要给证明。
不严格证明:在不超过k的前提下。显然如果较近的*可以有解,那么较远的*也一定有解。然后题目要求尽可能少的改*,那我显然选较远的咯。
代码:
C: Double-ended Strings
题意:
给你两个串a和b。然后你每次可以把a或者b里开头或结尾的字母拿掉。问最少多少次操作后,能让剩下的ab一样。
思路:
经典最长公共字串嘛。但是,看看数据规模才100组,ab的长度才20。我反手就是n^4直接暴。
枚举a串可能的字串,然后拿到b串里暴力看是不是也是子串。连KMP都省了。
代码:
D: Epic Transformation
题意:
给你一串数a。每次你能在里面选两个不同的的数字拿走。问:最少可以剩几个数。
思路:
统计每个数字出现的次数。然后每次拿出现次数最多的两个数字。一直模拟拿就行了,最多就10w次。
代码:
E: Restoring the Permutation
题意:
存在一个1-n的排列p。也就是p里面由1-n这n个数字组成,每个数字出现一次。比如[3,5,2,1,4]。
定义数组q。q[i]=max(p[1], p[2],..., p[i])。也就是前i个数中的最大值。
现在给你q。问你所有可能的p里面,字典序最大的和最小的是什么。
思路:
贪心。贪心方法的证明是自明的。
因为q显然是单增的。那么当q[i]不等于q[i-1]时候,p[i]=q[i]。
当q[i]=q[i-1]的时候,字典序要最大,就去剩下的数里找比q[i]小的最大值。要字典序最小,就找比q[i]小的最小值。
代码:
TreeSet真好用。水题。
F: Triangular Paths
题意:
如下图所示的三角。首先边是单向的。其次边分为激活和未激活。默认状态下,层数r+位置c的和为偶数就是左边的边被激活,和为奇数就是右边的边被激活。
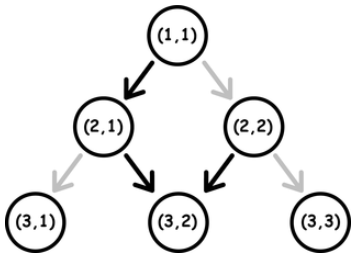
每次操作可以改变一个点往下的边的激活情况。现在从(1,1)出发,要求经过一系列点,问你最少要改多少次状态。
思路:
这个题感觉勉强Div2B题的水平了,但其实还是太水了。稍微观察就会发现,和奇数的点往右之后会继续往右,进而形成另一种“层”。
于是往下走需不需要改状态只需要看需要通过多少个“奇数层”就好了。唯一需要注意的是,如果下一个要到的点本身就出于同一个“偶数层”,那么每一步都要改状态。
代码:
G: Maximize the Remaining String
题意:
给你一个串s。然后呢,每次可以把重复的字母任意去掉其中一个,反复操作。问去掉所有重复字母后,字典序最大的结果是什么。
思路:
我居然WA了一发……我菜……
既然是字典序最大。那从结果的第一个字母开始往后依次求解。
每次都尽可能选最大的字母,但是要注意的是选的字母要保证还没有出现的字母在这个字母出现的位置之后仍然能出现。不然就会漏字母了。对于选的字母如果有多个可选位置,就尽量选前面。
代码:
总之,除非是为了练手速,或者测脑残值,不然不会碰Div3。太水了。我为什么要浪费时间写他?而且我为什么要浪费时间写这个题解?