
上一篇,我们已经实现了一个非常不好用的路由器。那么现在我们就可以把一开始拿掉的东西给重新拿回来。
所以,这里我们将集中于辅助功能。
这一块的东西就非常杂了。如果说,上一篇会需要一点点深度的话,那么这一篇需要的就是一点点广度。
实在是个人状态不好。review能省就省了,有啥语句不通,错别字什么的,还请见谅。
DHCP server
比起别的,个人认为DHCP server是提升体验最大的东西了。一方面,给每个server一个一个的配置IP是个很痛苦的事情;二方面,DHCP可以给每个server提供一个外部的DNS;三方面,安全问题很重要,但安全问题在被攻击之前,都是一点不痛的。
什么是DHCP
DHCP毕竟是P结尾的,所以这个东西本身是一个协议,全称是Dynamic Host Configuration Protocol。类似于HTTP,有协议就有对应的server。
除了家庭场景下,我们是因为懒惰而不愿意给每一台设备手动指定IP这个理由之外。DHCP还能提供不少好处。
首先,可以避免IP地址冲突。比如两台设备都说自己的IP是192.168.1.100。那么根据上一篇里NAT的原理我们发现,这样是没法上网的。有了DHCP,至少你不再需要记住其他旧设备的IP。
其次,变更方便。这里不止是改变所有设备的IP段,还包括统一修改所有设备的DNS配置。
最后,信息集中。所有由DHCP分配IP的设备都在一个list里。因此,我们可以根据这个list来检查网络里是否有什么陌生的设备(聊胜于无,安全问题后面会专门写)。
DHCP既然是负责分配IP的,那么问题就来了,新设备是如何找到DHCP server的呢?
这里就不得不提到广播了,广播是IP层的一个东西,也就是说是IP协议的一个东西。他允许网络中的设备把一个发送一个消息给网络中的所有设备。再具体一点就是,提前约定好了255.255.255.255就是广播地址。
有了广播,DHCP的实现方式就很好理解了。其实就4步:1. 设备发送广播,看看网络内有没有DHCP server;2. DHCP server回应说:有,我的IP是192.168.1.1;3. 设备给DHCP server发送请求说要一个IP;4. DHCP server给设备分配并回复。
根据DHCP的原理,立刻就能发现:一个局域网内,有且只能有一个DHCP server。
除非这两个DHCP server之间有同步,否则在第一步之后,如果有两个DHCP server回应了,于是IP的分配就会混乱。
(我没有研究过怎么搭DHCP集群,我个人只会单点)
搭建DHCP server
对于Ubuntu我记忆中是有预装DHCP server的,而且会主动去读取Netplan的配置。如果不是也没关系,这个也不是什么魔法,也就只是一个软件罢了。
安装就是安装一个叫做isc-dhcp-server的包就可以了。剩下的就是配置的问题。
配置也和netplan类似,就只需要修改/etc/dhcp/dhcpd.conf就可以了。我们直接看一个样例配置:
default-lease-time 600;
max-lease-time 7200;
authoritative;
subnet 192.168.1.0 netmask 255.255.255.0 {
option domain-name-servers 192.168.1.1;
option subnet-mask 255.255.255.0;
option routers 192.168.1.1;
option broadcast-address 192.168.1.255;
pool {
deny unknown-clients;
range 192.168.1.101 192.168.1.200;
}
pool {
allow unknown-clients;
range 192.168.1.10 192.168.1.50;
}
host printer {
hardware ethernet 02:07:34:76:02:b1;
fixed-address 192.168.1.100;
}
}
可以看到,前两行制定了IP的默认有效期。因为DHCP的分配不是永久的,而是分配给设备一段时间。这样将来设备离开,也会把IP释放出来给别的设备用。
然后第四行开始我们详细的指定了内网的IP分配。第四行本身是指定这个子网的IP段。
第五行我们制定了DNS server为路由器的IP。当然也可以换成114.114.114.114,这样所有设备默认都会用114作为DNS server,就可以省去路由器的DNS。
后面两个pool块,是我们指定的两个IP池。可以看到一个allow陌生的设备,一个是deny。也就是说,对于陌生的设备我们从一个特殊的IP段给他分配IP。
最后,一个host块,我们指定了一个叫做printer的设备,根据其MAC地址,分配了一个固定的IP。
DNS server
这个果断上Docker,直接使用CoreDNS就好了。CoreDNS的可靠性还是不错的,毕竟K8S也在用。具体可以参考我之前写过的介绍。
 xloypaypa
xloypaypa当然,也可以选择其他更强大的工具。但我个人目前主要还是使用CoreDNS,对其他工具的了解不多。
Firewall
如我们上一篇里介绍的,Iptables就是操作firewall的一个工具。不得不说,Iptables可以说是这几篇水文里最不水的东西了。但iptables是个宝藏,因为他涉及网络的各个方面。

防止设备访问路由器
我们不会希望所有人都能有能访问路由器。
比如,我们不会希望上游的光猫网络层面上有权限连接到路由器的ssh,我们可能也不希望访客网络的用户能访问路由器的后台界面。
这里我们需要定义以下“访问”。这里的访问是指,最终目标是路由器的流量。也就是说,通过路由nat出去的流量,因为目标不是路由器,所以不是在“访问”路由器。
显然,访问路由器的流量,在路由的时候,就不会被路由出去。所以这里的流量在中间路由的时候,就不会走到右侧,而是向上往应用层走。
所以不难发现,这个流量会经过input链。理论上其实nat表、mangle表、filter表都可以,但是考虑工程实践,我们过滤数据包的需求还是就在filter表里做好些。因此,我们需要配置filter表的input链。
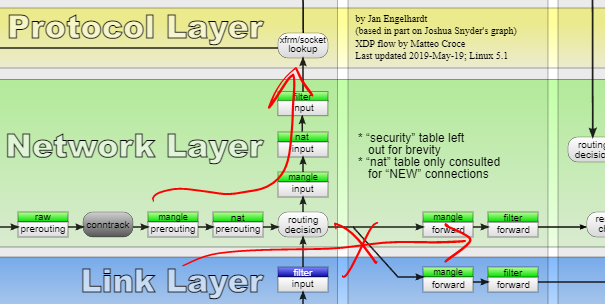
具体规则其实是个见仁见智的事情,如第一篇里我就说过,其实允许任何人网络层面上可以访问路由器也不是不行,只要我们对路由器的各方面权限控制很有信心就行。
而我个人而言,我是不相信我自己的配置的。因此,下面的配置,是采取最小权限原则,能不让访问就不让访问。
第一条配置就是,input链默认drop所有网络包:iptables -t filter -P INPUT DROP。其中-P是Policy的意思。
第二条配置是:允许接外网的网卡接收已经建立的TCP连接:iptables -A INPUT -m conntrack -i eth0 --ctstate ESTABLISHED,RELATED -j ACCEPT。因为,根据NAT的原理,TCP的回复在被逆·NAT之前,首先得允许上游发回来。
接着第三条配置是,允许某个物理网口访问:iptables -A INPUT -i eth1 -j ACCEPT。
最后,允许路由器访问自己iptables -A INPUT -i lo -j ACCEPT。
这里需要提醒:如果是通过ssh配置这个,需要倒着来,也就是先配lo,再配eth1,最后配Policy。 因为如果先配Policy并且生效,ssh的连接就没了。
(为了方便,个人建议直接给路由器接键鼠显示器,直接配置。)
这个配置的意图是:物理隔离。除非给那个物理的网口插上了网线,否则没人能碰路由。
我个人的实践是:服务集群和主力开发机允许访问路由器。开发机访问这个是自然的,集群访问的目的是允许远程操作路由器。这里的考量是,内网的访客设备(包括手机)不可信,服务集群如果被攻击,我技不如人那我认栽。
上网白名单
这个主要是防蹭网。
类似的,要防止未知设备通过路由访问网络,我们可以通过MAC地址白名单的方式实现。显然,上网需要路由NAT,那就是走上面图里右侧的路。那么类似的,这里我们需要配置filter表的forward链。
同样也是见仁见智。我这里给出我最小原则下的方式:
- forward链也是默认drop所有包。
- eth1这张有权的网卡,且MAC地址符合的的设备ACCEPT:
-A FORWARD -i eth1 -o eht0 -j MACWhitelist和iptables -A MACWhitelist -m mac --mac-source 02:07:34:76:02:b1 -j ACCEPT。(这里我创建了一条自定义链MACWhitelist,然后在MACWhitelist里判断MAC地址,也就是说,INPUT链里来自eth1的流量,会交给MACWhitelist做判断,方便集中管理MAC地址) - 允许NAT回复的数据:
iptables -A FORWARD -m conntrack -i eth0 -o eth1 --ctstate ESTABLISHED,RELATED -j ACCEPT - 访客网卡允许访问,做法类似,只是不用跳MACWhitelist,直接ACCEPT即可。
其中#2是允许内网设备,顺着eth1,通过连接外网的eth0,nat forward出去。#3是允许返回的数据由eth0,通过连接内网的eth1,返回内网设备。
这里看上去有点奇怪。似乎访客网络具有更高的访问外网的权限。这里其实两个原因:
1. 服务集群纯有线网络。自己用的手机也是访客网络,权限高点很正常。
2. 访客网络是eth2,这张网卡无权访问路由。
另外,这里如果把#2和#3的eth0这张网卡改成eth2,就可以实现服务集群访问访客网络,但是访客网络不能访问服务集群。
总的来说,如果能理解上一篇的MVP的操作,那么这里就非常灵活。
限速
访客网络的体验往往不是最重要的,所以对网络进行限速很正常。但是需要注意的是,iptables我们一直针对的都是数据包,所以我们其实不能直接限制他的下载上限为100kb/s。
我们能做的是限制TCP的数据包数目和连接数目,然后根据tcp数据包的大小限制,自己算对应的最大网速是多少。具体操作:
iptables -A FORWARD -m limit -m connlimit -i eth2 -o eth0 --limit 1000/second -j ACCEPT --connlimit-upto 100
其中-m limit -m connlimit是表示有limit和有connlimit。--limit 1000/second表示允许每秒1000个包,--connlimit-upto 100表示最多100个连接。
到此为止,我们完成了一个相对还算标准的路由器。也预留出了大量的可进一步扩展的方向。到此,Ubuntu做路由的主要内容也就算是结束了。