
在一个月黑风高的夜晚,我家的路由突然“断网”。但又没有完全断,而是卡在了一个非常诡异的状态。经过两天晚上的努力,最终发现是NAT失效。
这次调试,算是对iptables的四表五链的一次生动的应用。同时,也借此机会进一步熟悉了相关的工具链。

路由器“断网”
一切是突然发生的,那一天晚上,没有定期的patch,没有任何手动修改,甚至也没有多少流量从那一台路由器过。
断尤未断的现场
获知断网的消息不是我的监控告警,也不是我自己发现某些服务不可访问。而是我家里的人告诉我。
这其实很不寻常,因为如果是路由器断网,那路由器后面的集群也会立刻断网。那我的监控会立刻向我告警。而且,集群断网的情况,监控应该会尝试透过所有可能的信道通知我。基本就是“呼死你”的模式。
所以我收到抱怨的第一反应是不信的,我立刻打开了我的监控。发现监控里,集群的各种状态信息依然在实时更新。各项服务运转正常。但是,当我尝试ssh到集群时,发现始终无法连接。
此时,我草率的认为,是不是连接太多了爆掉了?虽然不知道为什么会有那么多连接,但是重启再说。结果重启了路由器之后,监控里的集群也再也没能上线。
集群断网,但路由器没事
集群下线之后,我只能认为所有设备都失去了网络。于是联系家人开始离线调试(家人4G开zoom,摄像头拍屏幕调试)。
我选择直接开始离线调试是因为我立刻想到了最坏的情况:路由器由于气温过高,直接烧了。需要彻底重装。
但是,接上显示器之后,发现路由器竟然能够正常开机!不仅能正常开机,而且在路由器上竟然能通过curl访问外网!
更离奇的是,从路由器出发,可以ssh到内网的集群。也能从内网集群的机器再反过来ssh到路由器上。
也就是说,路由器到外网的连接没问题,路由器到内网的连接也没问题。
路由器配置检查
既然路由器两端的连接都是OK的,那自然就会怀疑到路由器出了问题。而路由器的问题无非是:
1. ipv4转发被关了,导致流量直接被拒绝转发。
2. NAT的规则配置不当,导致转发到错误的网卡。
3. DHCP配置不当,导致IP地址冲突或者路由表冲突。
4. DNS server配置不当,导致DNS无法解析。
5. 路由规则配置不当,导致ip走到错误的网卡。
但是,经过仔细检查。所有的配置都没问题!(后面证明配置本身确实没问题)
所有的配置都没问题,那就意味着所有的地方都可能有问题。所以就只能一个个逐一排查了。
排查过程
坦白的说,实际的排查过程并没有按照下面写的顺序。基本上是想到啥排查啥,也就是没啥章法。主打的就是一个悟性。
下面排查过程的顺序主要是从易到难排序,或者更准确的说,是按照我的熟悉程度排序,我越熟悉的排在越前面。(顺便吐槽一句,确实岁月改变了我,我现在干啥的都讲究一个排名必须分先后,分尊卑,分长幼,2333)
DNS server
这个最好排除。如我前面的文章里说的,DNS server本就不是路由器的必备功能。所以直接跑到内网机器里直接用IP curl外部服务就好了。
结果还是不通。说明:不管DNS有没有问题,其他的东西一定有问题。
另外,直接nslookup一下,发现可以解析出域名对应的IP,所以也证明DNS是好的。
而且这进一步证明了“路由器和外网能联通”+“路由器和内网也能联通”的基本事实。
DHCP配置
这个也很好排除。一方面登录到内网机器里ifconfig一下,看看ip是不是之前指定的ip。另外可以在路由上看一下当前的IP分配情况。因为全是有线,所以设备数目是固定的,分配出去的IP也是固定的。
经过检查IP分配的结果没有问题。
另外在路由器是,可以查看DHCP server的运行情况。经过检查,没啥问题,服务正常运行。
ipv4转发和路由规则
从这里往下,就开始涉及iptables的操作了。首先经典iptables工作流程镇楼。

为了看路由转发是否正常,我们就需要根据路由前后的状态来看是否符合预期。如果正常工作,在"routing decision"这一步就会把收到的tcp包向右转发。
也就是说,如果转发正常,那么在filter表的forward链(当然mangle表的forward链也是可以的)应该能拿到一个去往正确网卡的数据包。
如果发现流量去往了input表,或者forward表里到的目标网卡不正确,就说明要么是ip的forwarding根本就没开,或者路由表的规则指示了错误的网卡。
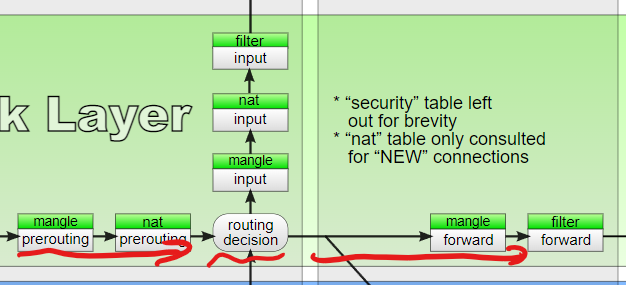
那么自然的,我们希望拿到forward表的log(当然,以防万一,input表的log也一并拿到)。这就需要用到iptables的LOG。
我们通过iptables -A FORWARD -d 8.8.8.8 -j LOG --log-prefix="[filter-forward]"添加一条规则。意思是,在FORWARD表里,当目标ip是8.8.8.8时,打一个log,log要以[filter-forward]开头。
当然,也可以添加更多网卡的筛选信息,这里只是为了方便调试,就随便找了一个外网的ip来看整个流程。
添加完规则后,到内网服务器curl一下。就能在/var/log/kern.log里看到相应的日志记录。
我当时试了一下,发现forward表这里拿到的是正确的网卡。且source ip是内网的ip(这是正确的,因为此时还没有发生做SNAT转换),目标的IP和网卡也都是正确的。
说明,ip转发和路由规则本身没有出问题。
NAT规则
既然路由规则没有问题,forward表里能拿到正确的网卡,那就顺着iptables的流程继续往下走。
此时经过forward表之后,应该会进行第二次路由表检查。但我个人感觉(不保真),这个只是对output过来的有用。毕竟不管怎么check,路由规则都是固定在那里的。
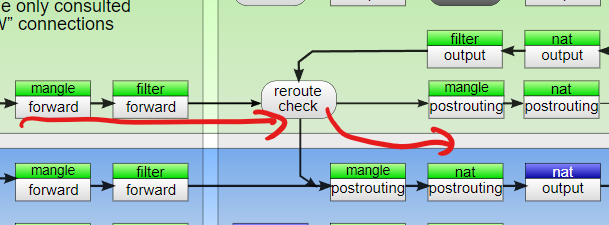
但这里有个问题:似乎iptables的log不能作用于nat表,而Masquerade这个动作似乎又只能在nat表的postrouting链上做。
所以,我们最多能在mangle的post routing上打个log。但这个log发生在SNAT这个动作前,除非route check真的有什么问题,否则这个log就不能说明NAT规则到底有没有问题。
我调试的时候也打了,确实没啥信息,也只是再一次说明,流量去往了正确的网卡,以及在进行NAT之前source ip的确是内网的正确ip。
考虑到nat的post routing之后,流量就彻底离开iptables了。所以就只能想别的办法来验证nat表的post routing是否工作。
这里就需要tcpdump直接看最后结果上,到底从哪张网卡上发出了什么包。通过tcpdump -i any dst host 8.8.8.8 or src host 8.8.8.8来查看所有去往/来自8.8.8.8的数据包。
这里-i any是指,任意网卡。不指定成-i eth1是为了再次确认路由表的确有在好好工作。
我当时尝试监控了一下,就发现了问题。在正常的路由器上面,tcpdump会记录2条去往目标服务器的数据包:
1. 一个内网ip到目标服务器的数据包。
2. 一个外网ip到目标服务器的数据包。
其中第一个包应该是接内网的网卡收到的,第二个是经过nat转换后从接外网的网卡出去的(因为tcpdump的时候网卡选的是any)。
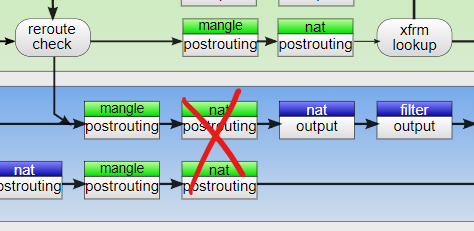
但是在坏掉的那台路由上,两个网卡的数据包的source ip都是内网ip。

这就说明,在nat表的时候,要么是规则丢失,要么就是什么奇怪的魔法导致规则失效。
所以结论就是NAT的post routing有问题。
问题的解决
显然,我没有改动过NAT表的任何规则。我也在路由器上让iptables打印出当时赈灾执行的规则,看了也没问题。
所以,一定是有什么厉害的东西,通过某种方式一定程度上改变了iptables的行为,使得nat表被跳过了。
于是我卸载了docker,问题就解决了。
会怀疑到docker的原因可以参考下面两个连接。一个是类似的问题,一个是docker的官方文档。
(虽然官网只是说forward表会被改成drop,但我本来就是drop。所以官网的文档只是让我愈发怀疑docker)
