
众嗦粥汁,微信、google chat等聊天工具自身的搜索功能是不太好用的。更可恶的是,这些聊天工具往往不会开放API接口来支持自动回复或者直接读取消息等。于是,不止模糊搜索,连精准搜索也成了一件麻烦的事情。
所以,退而求其次,既然API不让调用,那不如通过OpenCV把整个UI的各个区域识别出来,然后再使用OCR工具识别内容。
所以,本文主要是专注于:通过OpenCV,把整个聊天界面的结构分析出来,定位出每条消息的位置,以便后续OCR识别。(具体OCR使用看后面开不开坑吧)
本文的前置动作应该是:对操作系统进行截图。这里直接正常截图就好,不需要太高的精度,目的是给OpenCV识别后定位。
本文的后续动作应该是:根据识别出来的消息位置,对系统放大后再截图。最后再把大图给OCR工具识别。OCR工具我个人是准备上EasyOCR。(暂时不考虑飞桨)
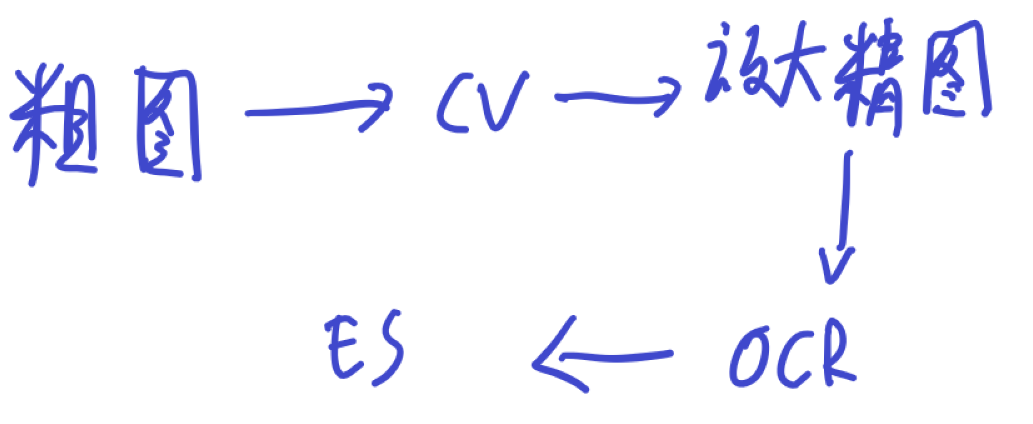
实现思路
我这里实现的思路就比较的简单粗暴,就献丑了:
- 识别聊天工具的整体框架结构,或者至少识别出聊天内容的区域。
- 在聊天内容区域中识别出头像。
- 根据头像的位置划分出一条条独立的消息。(显然,在大多数的聊天工具里,两个相邻的头像的最高点之间都是同一个人发的消息。那我们就根据头像的最高点来划分消息。)
这里我拿Google Chat举个例子:
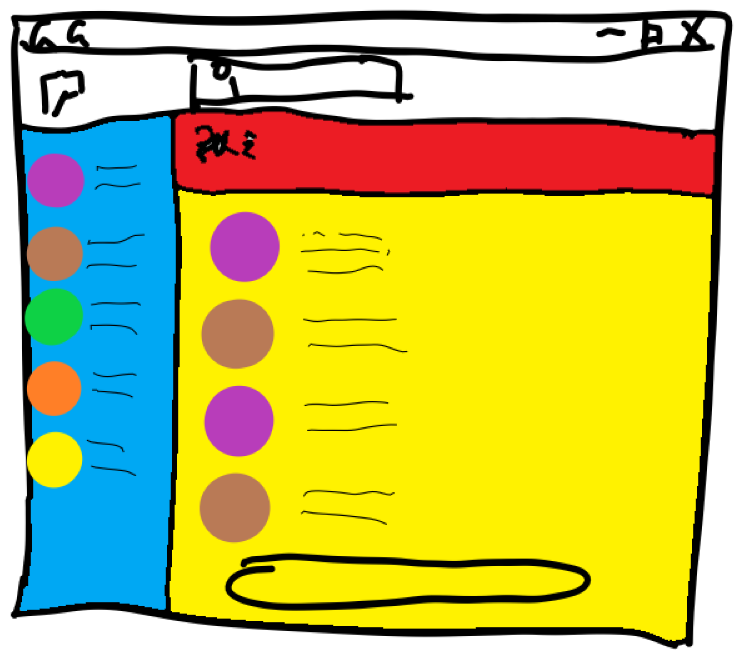
GoogleChat中,蓝色部分就是一个Contact list。然后红色部分就是聊天的对象。最后的黄色的部分就是主要的聊天内容的区域了。
我们在黄色的区域内识别圆形的头像即可。(GoogleChat中的头像为圆形,微信改成识别正方形即可)
这里需要多提一个点:就是我们为什么要先识别聊天区域。因为我们可以看到,蓝色的区域的头像和聊天区的头像往往是一个style。
最后,我们一旦有了头像。就可以快速的划分消息了。
识别页面框架
显然,正常的聊天工具都不会像我上面画的图那样歪歪扭扭。同时,不知道是不是什么页面布局的讲究,我发现不论是GoogleChat还是微信,都是左右分明。
我猜是因为要展示历史消息,所以通讯录就必然居左,且是一个长条。
所以我们可以先识别中间这条竖线。
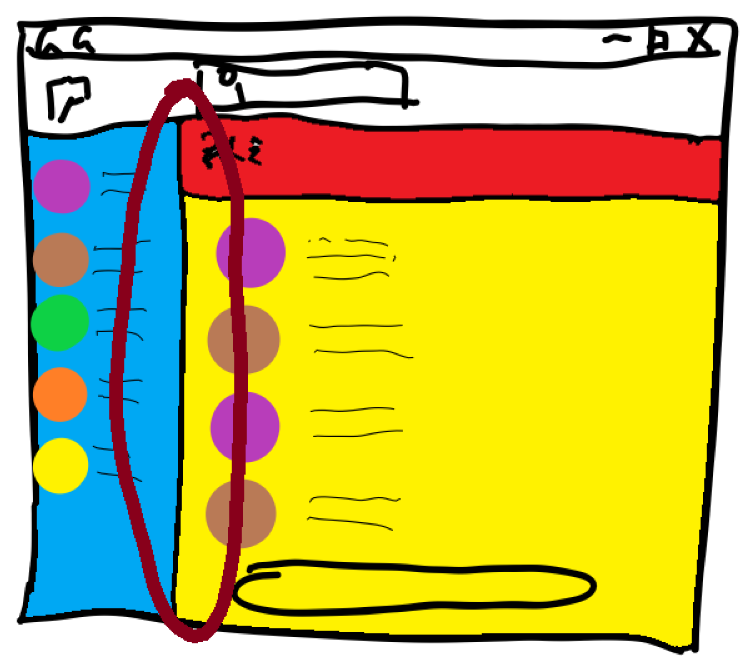
具体实现这个小目标就比较简单了:
- 灰度肯定还是要灰度的。(但其实也不一定的感觉)
- 用Canny做一个边缘识别。
这里甚至不需要太多的调参。因为中间这条线本身就是为了突出边缘,所以不论怎么调整参数这个边缘都能识别出来。(总不至于故意让你看不出来吧) - 边缘跑出来了就直接霍夫变换求所有的竖向的直线即可。
对于参数,我们可以参照整个图的高度的70%-80%来要求符合条件的点数。太高会因为中间的线不够长而识别不出来。太低可能会因为具体头像拼起来也构成一条线。 - 最后根据识别出非常有限的几条直线(毕竟,总不能这个聊天工具满屏幕全是竖线吧?)我们只需要伸出手指,数出对应的竖线即可。
到此我们可以轻松的把左边的Contact List给移除掉。于是问题就简化了:
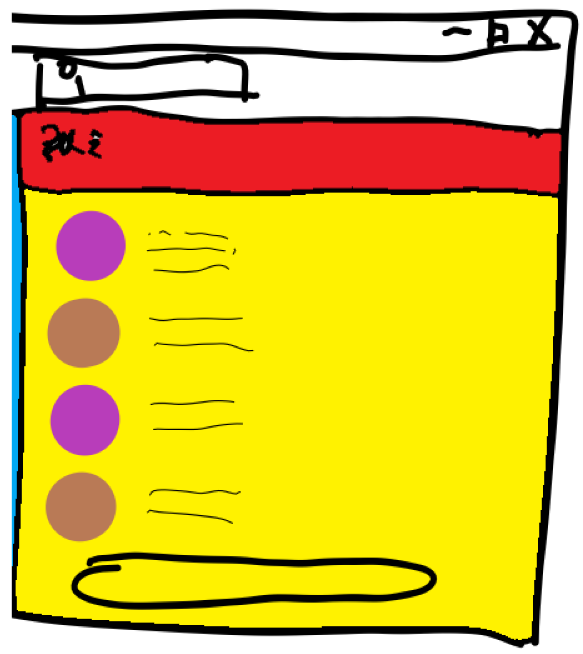
不难发现,剩下是几条贯穿全图的横线。类似的操作,再做一次,我们就能进一步找出聊天信息的区域。
识别头像
这时我们就可以开始识别圆形或者识别方形了。我的处理就比较的骚了。只能说还算是凑合:
- 灰度是肯定要灰度的。主要后面要二值化。
- 模糊化+二值化。这里的模糊化和二值化都要稍微猛一点。
原因是:头像这个东西有的人是头,有的人是狗。比如下面这个狗头,他就是扁的。
但只要我们足够模糊,然后二值化的足够的大胆,那么多扁的狗头,看着都是圆的。(类似于近视眼看不清)
至于微信,两个选择:1. 把方的模糊成圆的再识别;2. 毕竟微信的背景可以调,搞个骚的背景色,然后直接识别方形也行。 - 边缘识别+识别圆。这里正常识别就好,但建议大小限制要好好限制。

于是,我们就能找出一系列的头像和若干类似头像的狗头表情。剩下的问题就又转化成了如何排除掉狗头表情。
头像校准
正经的做法(我觉得的)
首先,我们可以注意到,聊天工具的头像往往都是在两侧,聊天的内容在中间。
可能这样可以显得是两个人在对话,或者像是博客回复。
想象一下头像在中间,消息在两边的聊天工具。就给人一种背对背拥抱的感觉。(也挺好,等我有钱了,我就做一个)
于是我们就只需要找最靠近的两侧的“头像”即可。具体操作(以google全在左侧为例):
- 直接找出最靠左的头像。
- 筛选出横坐标和最左的头像差不多的头像。
我自己的骚操作
对所有头像根据坐标点跑一个线性回归。大概的效果会像是下面这样:
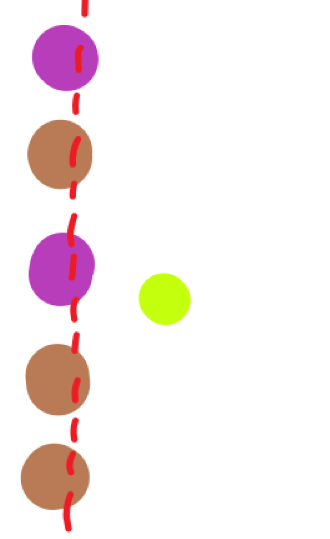
我们只需要排除掉距离回归出来的直线较远且在直线右侧的“头像”即可。
这样的好处是:骚。
这样的坏处是:如果某个人发了一堆狗头,这个线性回归的结果就比较糟糕了。
结语
到此,我们就有完成对消息的定位。
个人认为:识别整体界面结构还是比较清晰,方法也算得当。后面识别头像开始就多少有点离谱了。
但是,我们回到最初的目标:搜索。有了这一点,我们就能接受有限的重复。
因此,一个可能的改进:
通过多种方式识别头像,然后根据不同的结果划分消息,然后根据不同的划分多跑两次OCR就好了。最多入库的时候去个重。
比如这个带狗头的消息,就算是狗头被识别为头像了也无非是多了一张狗头和真正头像之间的没有字的图罢了。

至于OCR的准确度?我只能说,我菜,只懂调用,不懂炼丹。