
整体架构
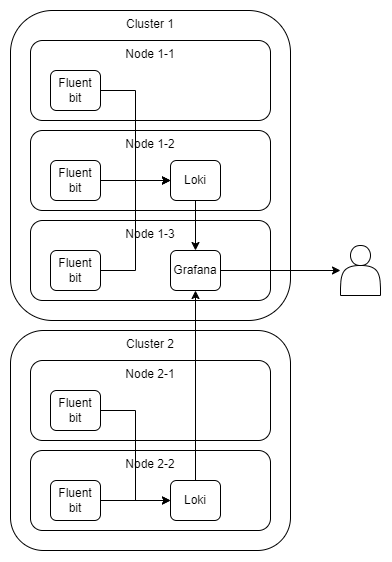
其中:
- Fluent bit自然是每个node跑一个。
- Loki是每个集群跑一个。至于分配到了哪个node,由k8s自己调度。
- Grafana是全局有一个就好了。独立部署在集群外也可以,只是我这里没有别的机器,不同集群权限上没啥差异,所以就直接部署到其中一个集群里了。
- Loki的持久化由k8s提供(日志存储)。
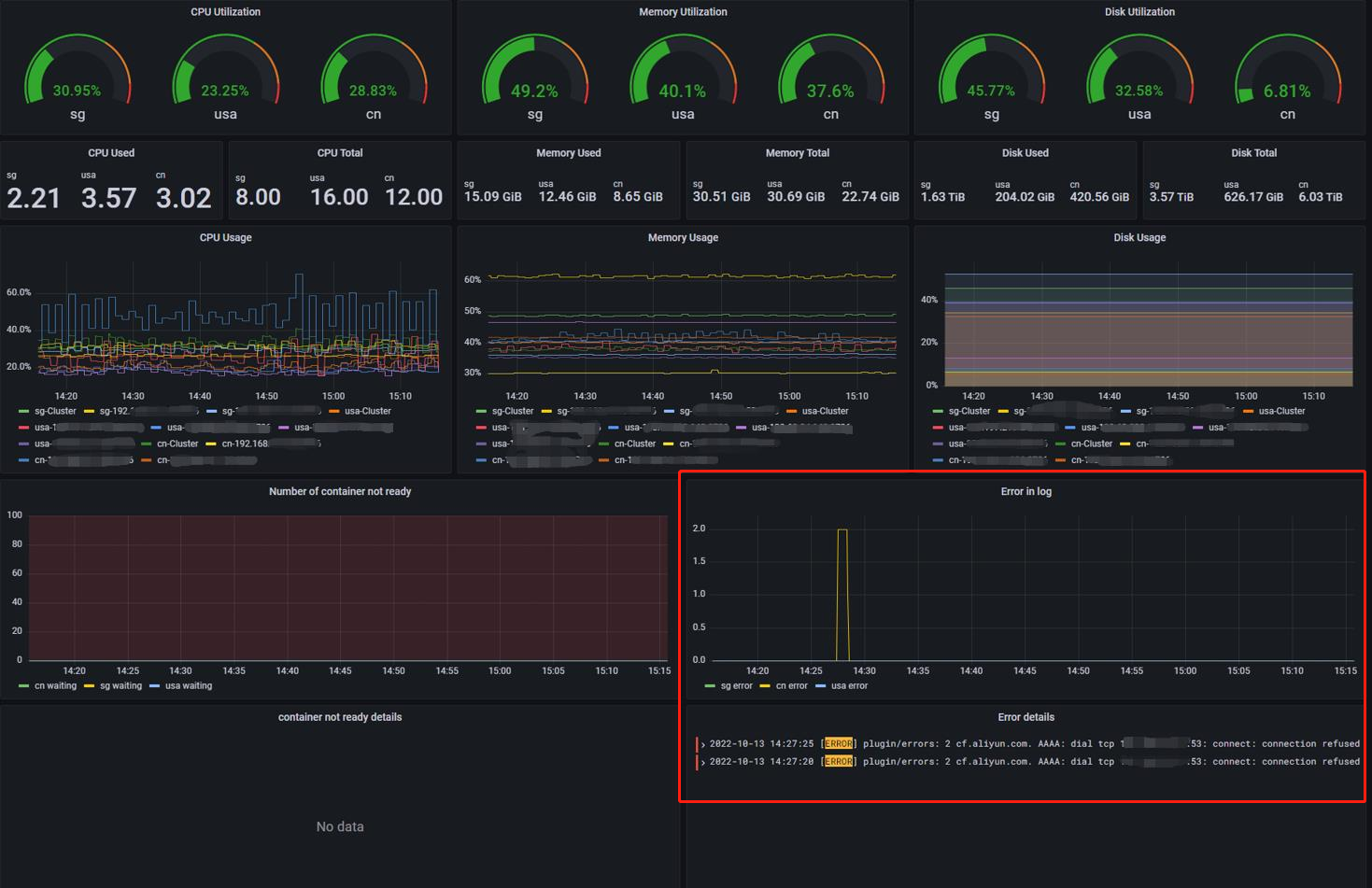
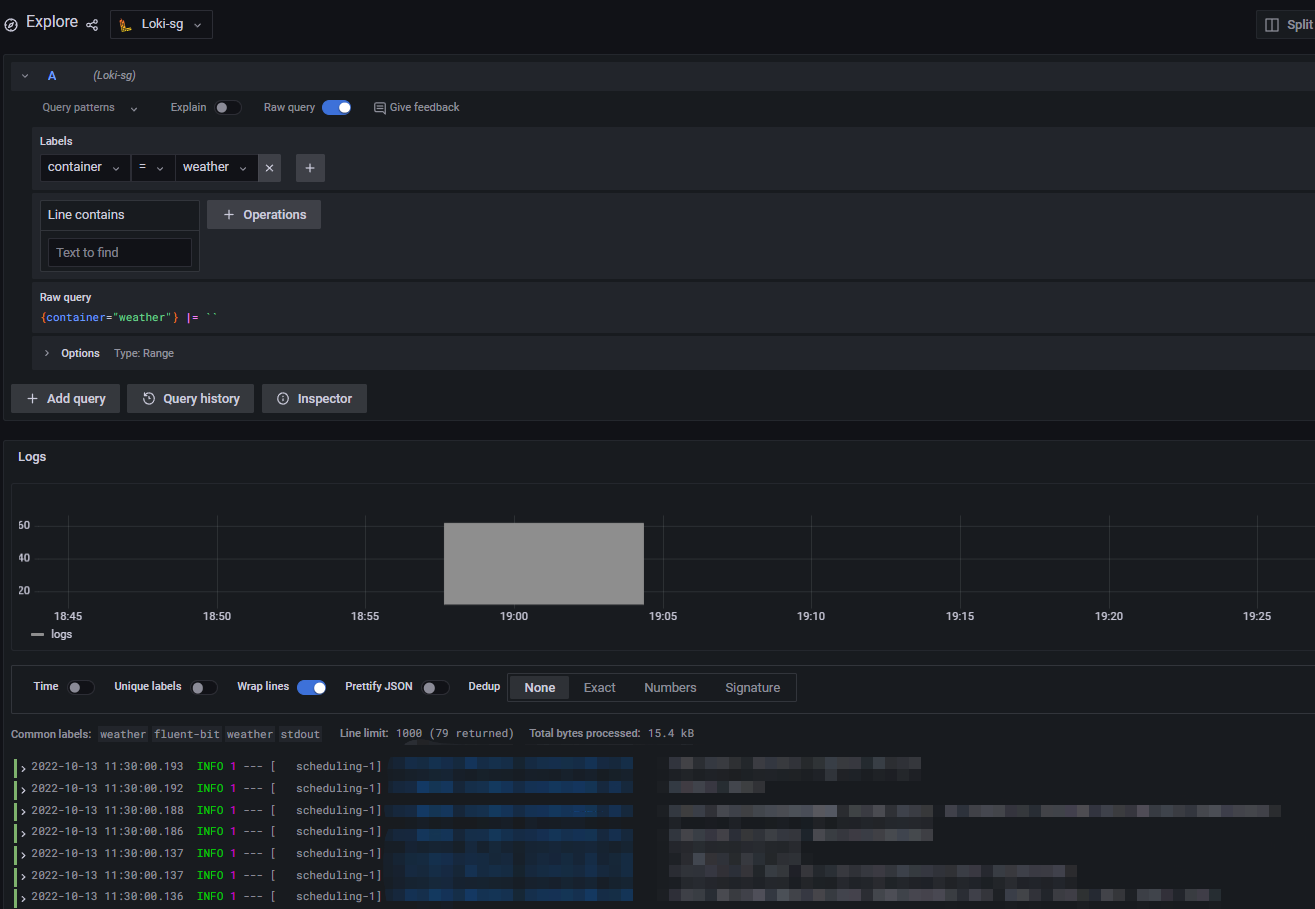
效果预览
为什么不是ELK/EFK
诚然我们知道,k8s的日志收集更著名的以套技术选型是EFK,所以这里说明一下为啥我会选择Grafana+Loki+Fluent bit的方案。
Grafana vs Kibana
个人认为,Kibana又贵又不好用。主要的考量点如下:
- LDAP集成:Grafana免费,Kibana必须是白金级。
- Webhook、发邮件等等告警操作:Grafana免费,Kibana必须是白金级。
- 权限管理:Grafana免费,Kibana必须是白金级。
Kibana的白金级订阅是125美元一个月。参考连接:
https://www.elastic.co/cn/subscriptions
https://www.elastic.co/cn/pricing/
至于好不好用,这个见仁见智。我觉得Grafana也挺好使的,而且Grafana也支持从Elasticsearch里拿数据。
但这里还是特别强调一下:天下无不是的工具。人家Kibana贵有人家贵的道理。
Loki vs Elasticsearch
这里可以直接参考这一篇文章:

我个人不走ES的几个原因:
- 内存短缺。而且按照我上面的架构,每个集群一个ES的话,内存开销更是可怕。(至于为什么Loki或者ES我是每个集群一个,这个下面会讲)
- 对Grafana的企业更加信任。毕竟Grafana愿意免费给你用一些基础的企业功能(比如LDAP集成)。
- Grafana第一方支持。图形化查询还是比较香的。

Fluent bit vs Logstash
这个考虑和ES有点类似。主要就是logstash又贵而且内存开销还特别大。
统一工具链
Grafana、Loki、prometheus都是同一家公司出的。Loki所使用的LogQL和prometheus的PromQL有非常高的相似性。
至少其基本概念和设计思路能明显看的出是一脉相承的。
这里强调一下Elastic好像也有类似prometheus的性能监控工具。
为什么不上MQ
MQ太重了,而且我机器不多。
设计思路说明
背景
首先,我三个集群分别处于这个星球的三个不同的地方。
两个是物理集群在家里,而且没有公网IP。暴露到公网的方式是内网穿透。
另外一个集群在云上。从内存到硬盘,每一个资源成本都很高。
其中一个集群,因为在成都,所以到其他集群的网络并不总是可靠(显然懂得都懂,我这里就只是在黑成都比不过其他真·一线城市的网)。
另外这个集群的到其他集群的流量也是走我自己的网(详见此文)。流量是非常宝贵的资源,8毛1G。
三个集群,三个Loki
显而易见,一个比较常规的做法是,所有集群的Fluent bit直接把日志forward到唯一一个Loki,就像所有集群公用一个Grafana一样。所以这里特别说明一下为什么我选择每个集群一个Loki。
首先是网络。一方面流量会产生费用,另一方面是网络线路的可靠性不够高。更可怕的是,长时间的访问甚至可能出于某种原因进一步降低网络的可靠性。所以这个是一个很大的担忧。
另外查询速率没有那么重要。显然,一个Loki与一个Grafana在同一个集群甚至同一个node可以大大减少日志查询的延迟。
然而,即便顶着绕地球一圈的延迟,日志查询主要的时间花费还是在Loki自身查询上。
而且,日志这东西,基本上是写的比读的多。所以读的时候的延迟只要不要太过分,有个1秒的网络延迟我觉得完全可以接受。
最后,最重要的是,部署简单。Grafana可以直接用helm直接一键部署好Loki+Fluent bit。部署、升级都比较容易。


Grafana在集群里
的确,Grafana直接部署在业务集群中可能不是一个很好的选择。尤其是alert也用Grafana来做的情况下。
我是确实遇到过运行Grafana的整个集群都down了,然后就真的是一点告警没有。
我这里是确实没办法。确实因为成本原因没办法为Grafana提供一个独立的机器。
集群间通信
因为三个Loki和一个Grafana的设计,同时又是Grafana主动访问Loki。所以这里就存在一个网络访问的问题。主要问题是连接方向和正常的日志推送相反。
我这里是在没有grafana的集群上做了一个内网穿透,穿透到Grafana。个人感觉不是很好。
数据展示
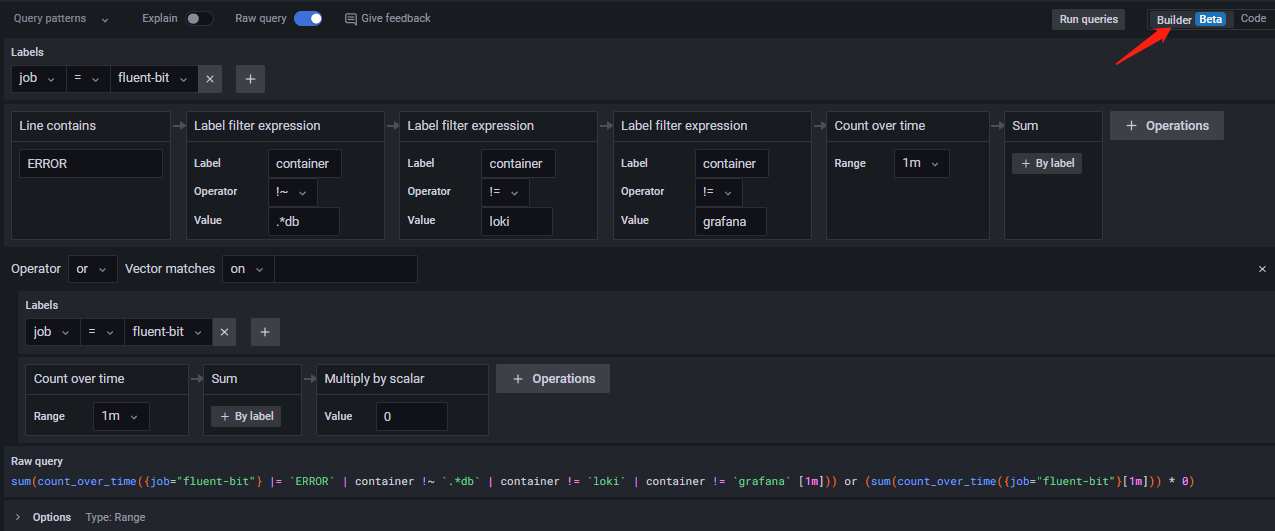
根据这一份回答,Grafana从7.3开始,支持一个panel同时使用多个数据源(截至本文,grafana已经到9.1了)。
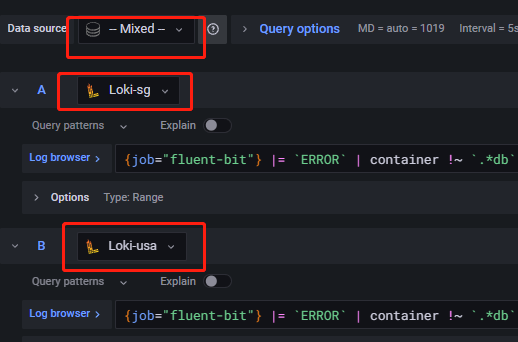
只需要添加多个Query就可以把各个集群的数据进行集中
日志告警
直接使用Grafana自带的alert功能就好了。
优劣分析
好的地方
- 成本较低
- 部署简单
- 工具链统一
- 图形界面查询
中规中矩的地方
- 统一的日志查询。(后端是集中的还是分散的不管,反正前端用户看到是统一的)
- LDAP或者Azure AD集成(包括从AD读Role来自动管理权限)
不好的地方
- 跨集群的内网穿透。(这个如果没有上面说的网络问题,把三个Loki集中成一个可以解决)
- 站在多集群的整体角度,Grafana构成单点失败。(有钱可以给Grafana单开一个集群解决)
- 日志存储和业务逻辑在同一个集群,一炸全炸。(还是集中成一个Loki可以解决)
- Loki偷懒没部署成集群,k8s调度期间的日志可能会丢失。(个人原因。但都有helm了,这个不是问题。)
总结
以个人非常有限的见识来说,70%的场景好用、够用、便宜。
剩下30%的高端场景我不知道但我觉得Elastic能行,毕竟贵有贵的道理。